Qihao Liu
Hi there! I’m a final-year Ph.D. student in Computer Science at Johns Hopkins University, advised by Prof. Alan Yuille. I hold a Master of Robotics at JHU. My research interests lie in the fields of generative models, adversarial examiners, 3D computer vision, and robustness.
During my PhD study, I have also spent great time at ByteDance (with Song Bai, Liang-Chieh Chen), Meta GenAI (with Mannat Singh, Xi Yin, and Andrew Brown), Google Research (with Yaojie Liu, Chengzhi Mao, and Vincent Chu). Before Hopkins, I received my Bachelors from Shanghai Jiao Tong University.
Research Interests
Over the past few years, I have delved in several fascinating research topics, including generative models, adversarial examiners, and 3D computer vision. My journey began with robotic manipulation using reinforcement learning and 3D computer vision. Recognizing robustness as a critical challenge for real-world applications of computer vision and other AI systems, I turned my focus to integrating human knowledge, graph-based models, and generative models to enhance both performance and robustness of vision systems. These efforts led to the development of adversarial examiner, which I further applied to generative models to systematically uncover and analyze their failure modes.
Recognizing that generative and discriminative models can enhance each other—through methods including adversarial examiners—and the relatively underexplored potential of generative models, I also focused on improving generative models for image, 3D, and video generation. For example, DiMR progressively refines details from low to high resolution, significantly reducing distortions and enhancing visual fidelity in image generation. CrossFlow introduces a novel approach for T2I generation by directly mapping between modalities with flow matching, bypassing the traditional reliance on Gaussian noise. DIRECT-3D establishes a new training paradigm for 3D generative models, enabling effective learning from large-scale, noisy, and unaligned 3D data sourced from the Internet. ReVision utilizes explicit 3D knowledge to improve video generation, particularly for generating complex motions.
I have also worked on topics including segmentation, video understanding, foundational object models, and 3D datasets during my internships and collaborations.
In short, during my PhD studies, I have been the core contributor to several projects that align closely with my research interests:
- Vision/Language Foundation Models [NeurIPS25, ICLR26, CVPR26]
- Diffusion Models for image [CVPR25, NeurIPS24, ICLR24], video [TMLR26], and 3D generation [CVPR24]
- Automatic Model Critic for evaluating and improving machine learning systems [ICLR24, CVPR23]
- Video instance segmentation and tracking [ECCV22, CVPR23]
- 3D human/articulated object pose estimation [Arxiv20, ECCV22]
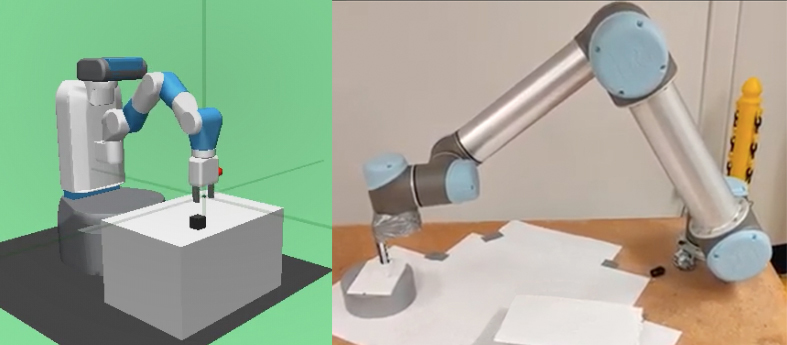
- Reinforcement learning for robot manipulation [IROS21]
Publications
Selected Papers:

Qihao Liu, Chengzhi Mao, Yaojie Liu, Alan Yuille, and Wen-Sheng Chu
Computer Vision and Pattern Recognition Conference (CVPR), Highlight, 2026
[TL;DR] AuditDM is an automated auditing framework that trains an MLLM to uncover its own weaknesses and failure modes, enabling annotation-free self-improvement that boosts PaliGemma2 and Gemma3 across 16 benchmarks and even allows a 3B model to surpass its 28B counterpart.
( arxiv | project page )
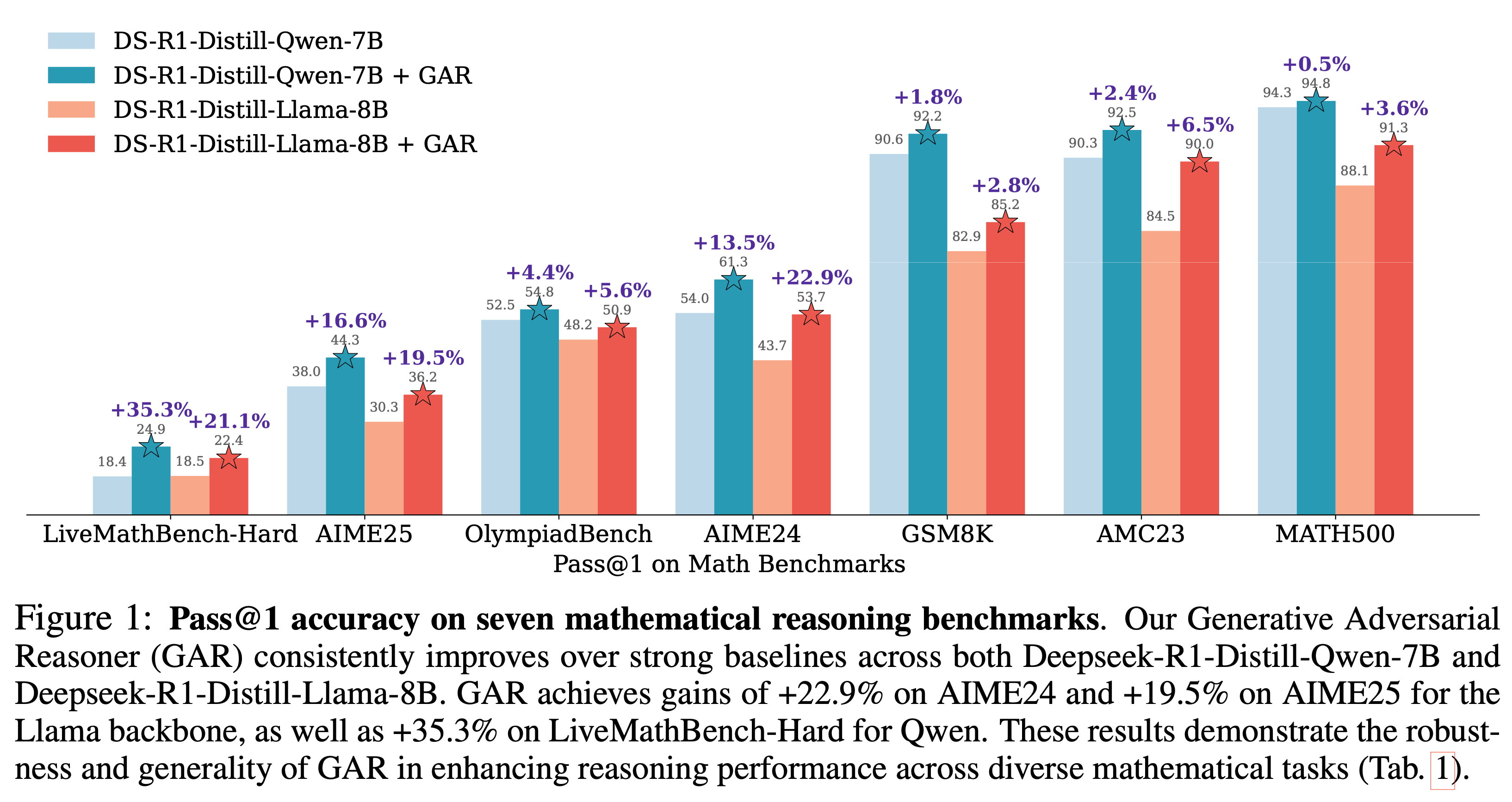
Qihao Liu, Luoxin Ye, Wufei Ma, Yu-Cheng Chou, and Alan Yuille
International Conference on Learning Representations (ICLR), 2026
[TL;DR] Generative Adversarial Reasoner is an on-policy adversarial RL framework in which a reasoning LLM and a discriminator LLM co-evolve to provide dense, step-level feedback, significantly improving the mathematical reasoning accuracy and efficiency of models like DeepSeek-R1-Distill-Qwen-7B across seven benchmarks.
( arxiv | code coming soon )

Qihao Liu, Ju He, Qihang Yu, Liang-Chieh Chen, Alan Yuille
Transactions on Machine Learning Research (TMLR), 2026
[TL;DR] We train explicit 3D priors to boost pre-trained models like Stable Video Diffusion, enabling high-quality motion generation with fine-grained control over details such as eyes and hands.
( arxiv | project page )
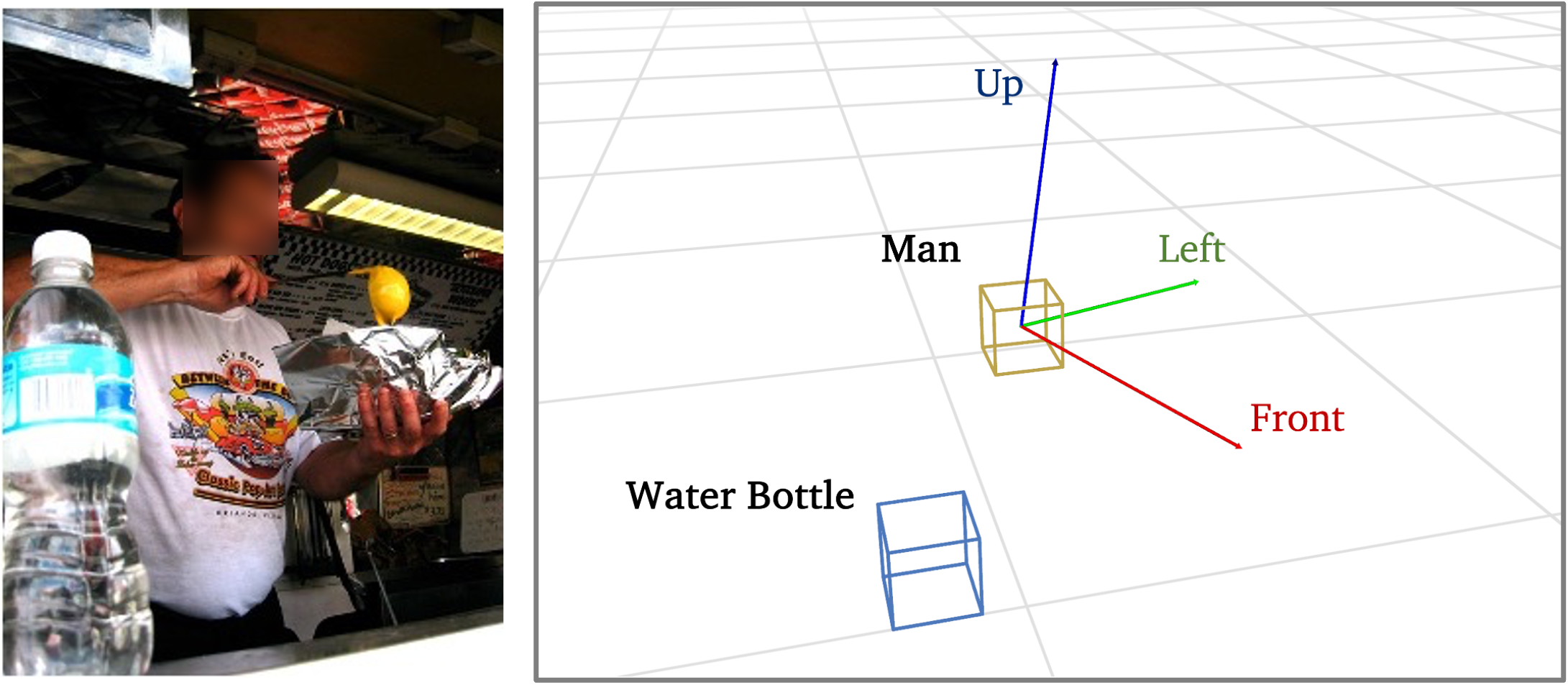
Wufei Ma*, Yu-Cheng Chou*, Qihao Liu* , Xingrui Wang, Celso M de Melo, Jianwen Xie, and Alan Yuille
(*Equal contribution)
Neural Information Processing Systems (NeurIPS), 2025
[TL;DR] Empowering VLMs with 3D scene understanding and reasoning over complex spatial relationships.
( arxiv | project page | code )
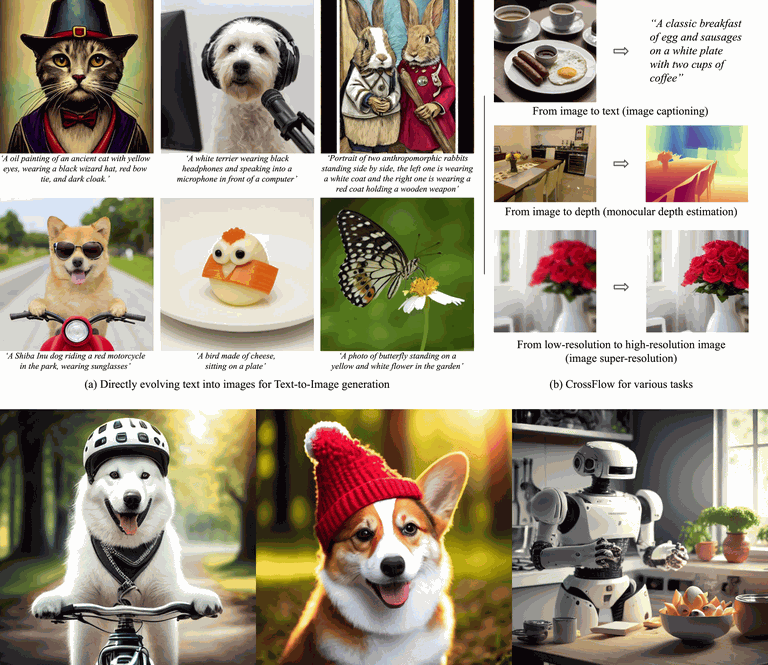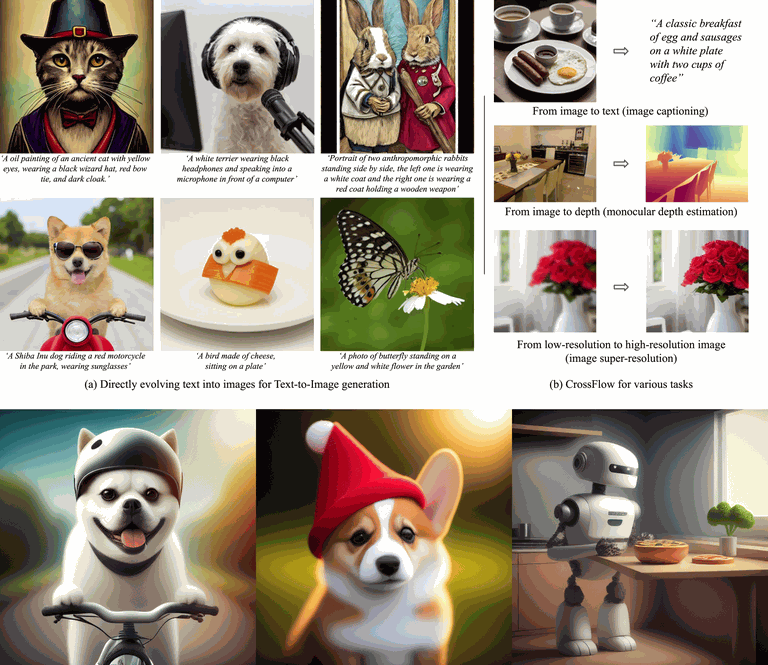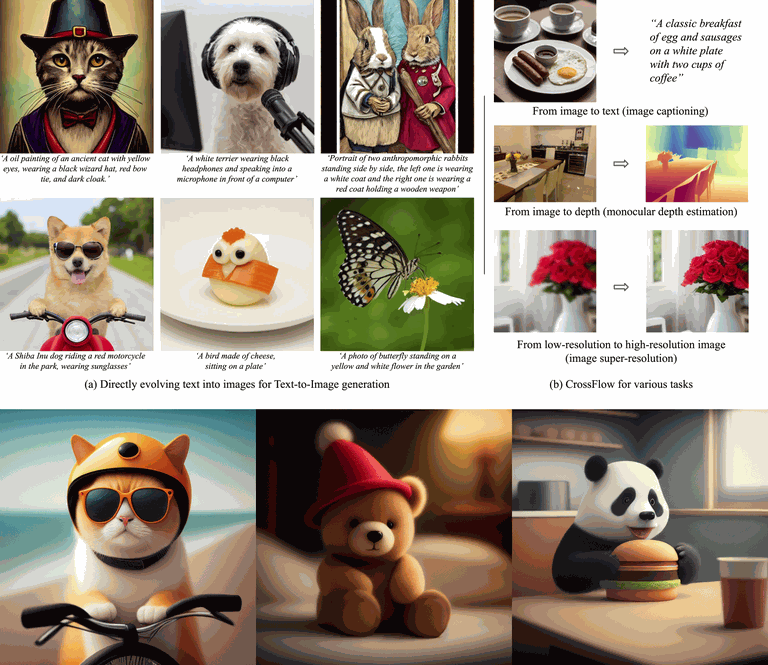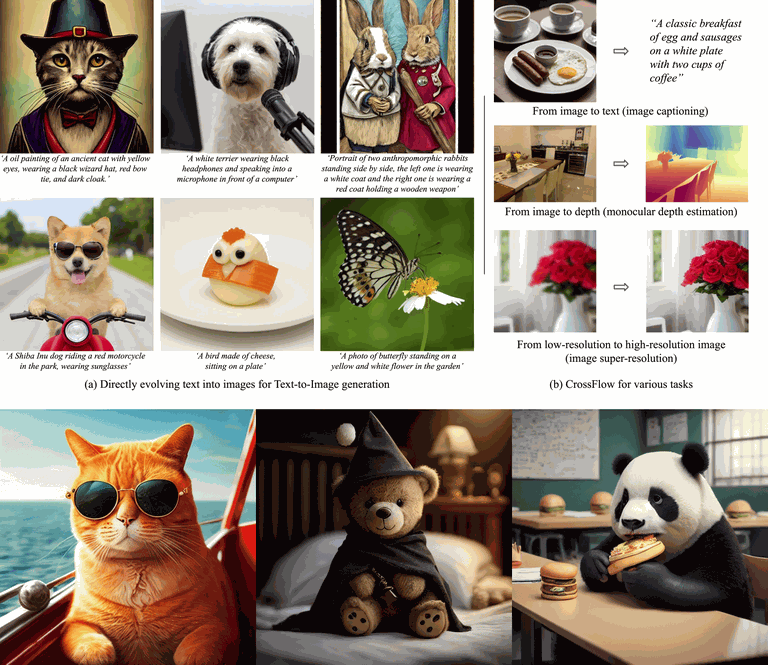
Qihao Liu, Xi Yin, Alan Yuille, Andrew Brown, Mannat Singh
Computer Vision and Pattern Recognition Conference (CVPR), Highlight, 2025
[TL;DR] CrossFlow directly maps between modalities using standard flow matching, without noise distribution, cross-attention, or task-specific tweaks, achieving SOTA in T2I, depth estimation, and captioning.
( arxiv | project page | code | HuggingFace demo )

Qihao Liu*, Zhanpeng Zeng*, Ju He*, Qihang Yu, Xiaohui Shen, Liang-Chieh Chen
Neural Information Processing Systems (NeurIPS), 2024
[TL;DR] DiMR is a new diffusion backbone that achieves SOTA image generation. For example, on the ImageNet 256 benchmark, DiMR with only 505M parameters surpasses all existing image generation models (including those with billions of parameters), without extra tricks.
( arxiv | project page | code )

Qihao Liu, Yi Zhang, Song Bai, Adam Kortylewski, Alan Yuille
Computer Vision and Pattern Recognition Conference (CVPR), 2024
[TL;DR] DIRECT-3D is a new text-to-3D generative model that directly generates 3D contents in a single forward pass without optimization. It also provides accurate and effective 3D geometry prior for other tasks.
( arxiv | project page | code )
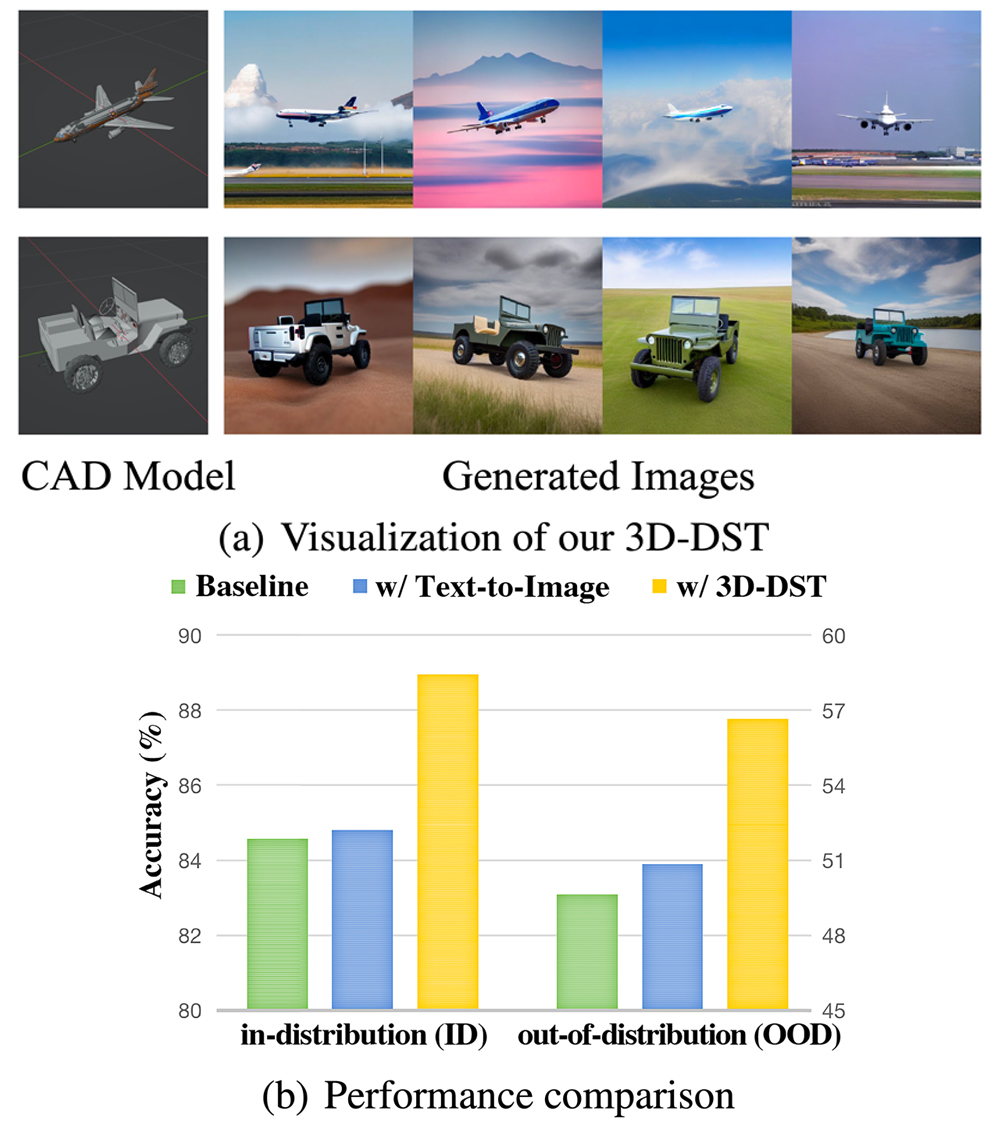
Wufei Ma*, Qihao Liu*, Jiahao Wang*, Xiaoding Yuan, Angtian Wang, Yi Zhang, Zihao Xiao, Guofeng Zhang, Beijia Lu, Ruxiao Duan, Yongrui Qi, Adam Kortylewski, Yaoyao Liu, Alan Yuille
(*Equal contribution)
International Conference on Learning Representations (ICLR), Spotlight (Top5%), 2024
[TL;DR] 3D-DST simplifies 3D geometry control in diffusion models, enabling structural edits and automatic 3D annotations in generated images. These images improve various 2D and 3D tasks, like classification and pose estimation, in both in-distribution and out-of-distribution settings.
( arxiv | project page | code | dataset )

Qihao Liu, Adam Kortylewski, Yutong Bai, Song Bai, Alan Yuille
International Conference on Learning Representations (ICLR), 2024
[TL;DR] SAGE is the first automated method to systematically uncover failure modes in diffusion models by exploring discrete prompt and high-dimensional latent spaces. We analyze failure modes in SOTA generative models, revealing four unexpected behaviors not previously studied systematically.
( arxiv | project page )
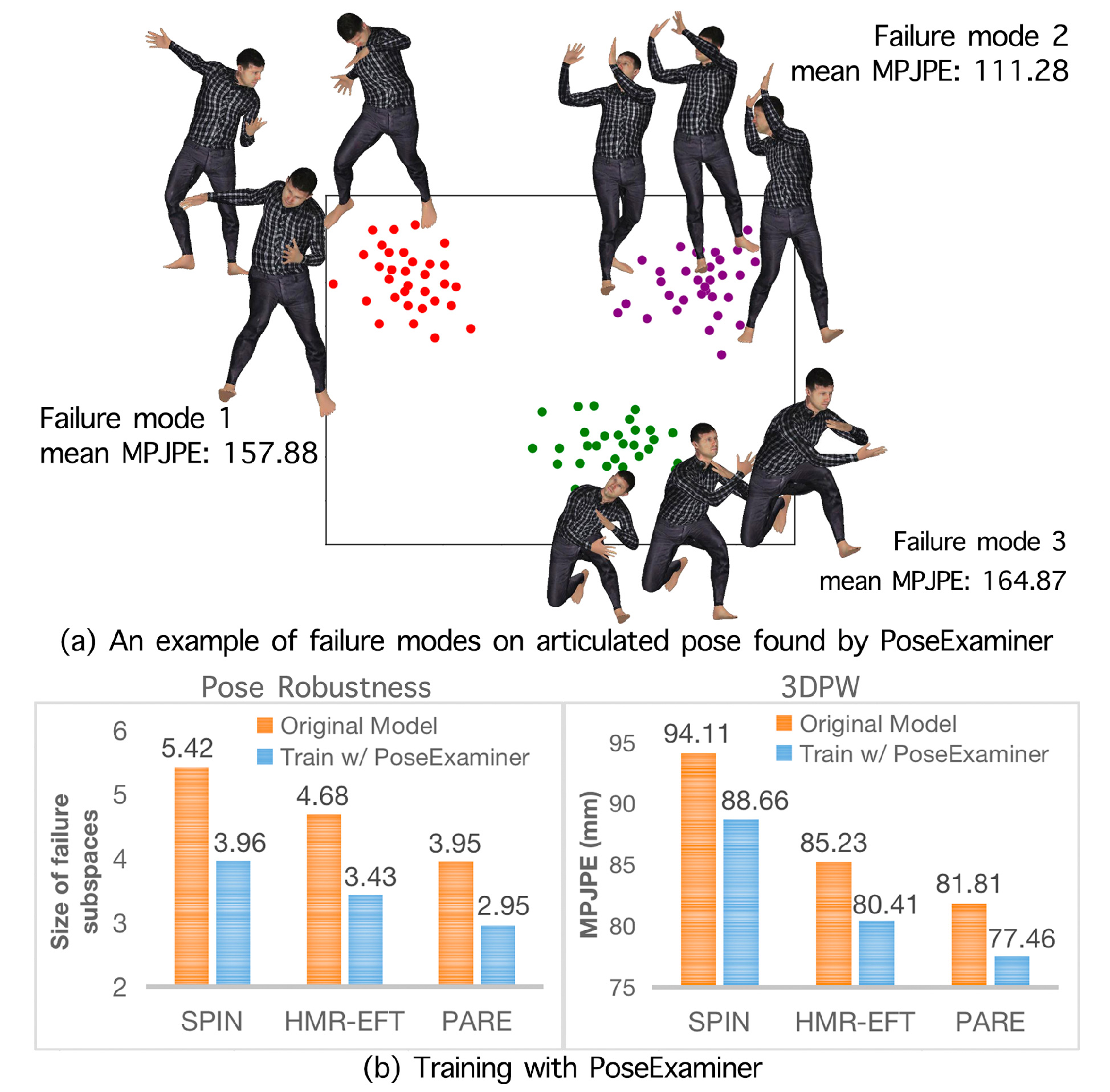
Qihao Liu, Adam Kortylewski, Alan Yuille
Computer Vision and Pattern Recognition Conference (CVPR), 2023
[TL;DR] PoseExaminer is an automated tool for evaluating HPS methods, identifying failure modes to assess performance and robustness. Fine-tuning based on these failure modes significantly boosts both robustness and performance on standard benchmarks.
( arxiv | code )
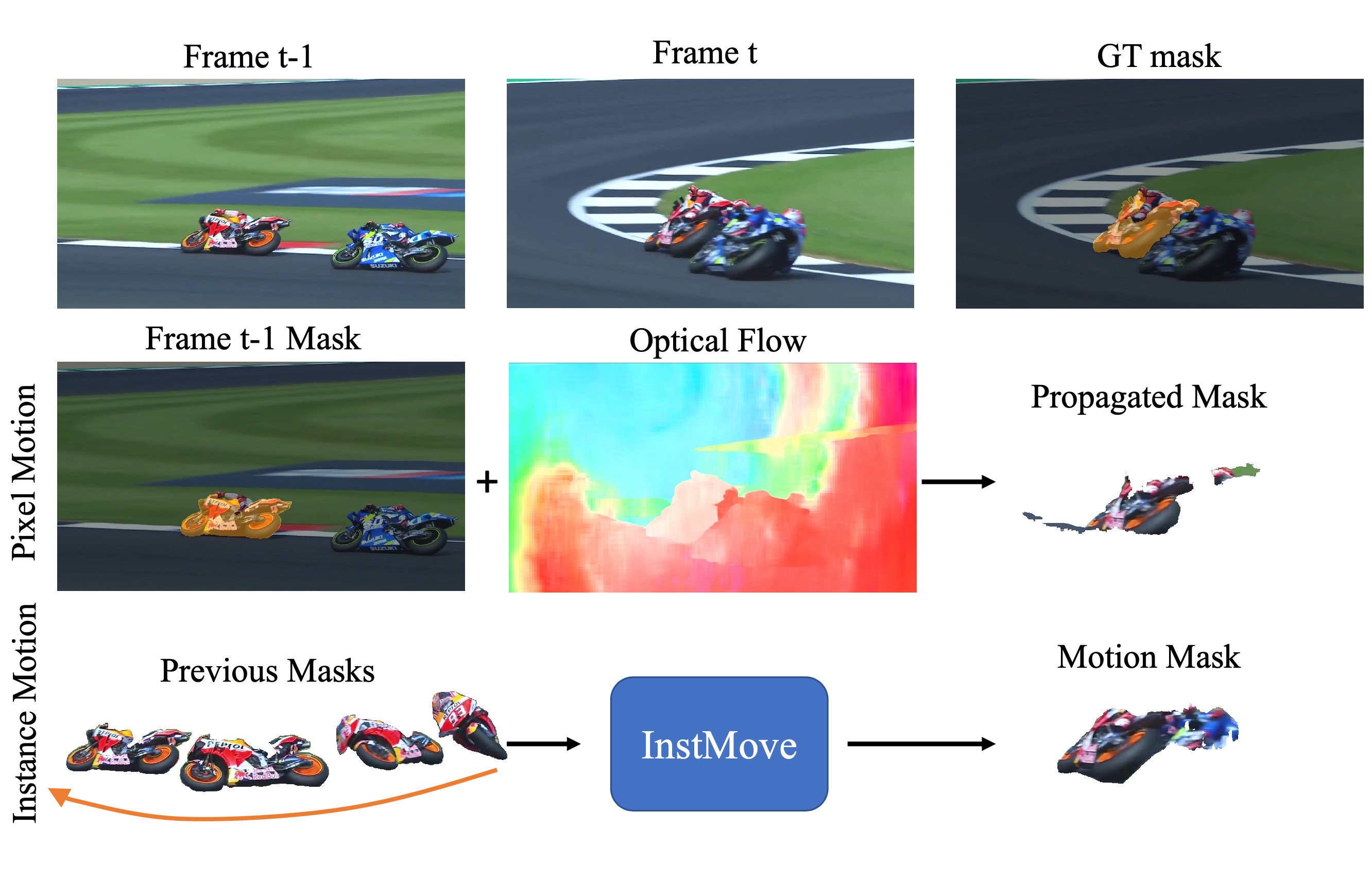
Qihao Liu*, Junfeng Wu*, Yi Jiang, Xiang Bai, Alan Yuille, Song Bai
(*Equal contribution)
Computer Vision and Pattern Recognition Conference (CVPR), 2023
[TL;DR] InstMove predicts instance-level motion and deformation from previous instance masks, providing accurate and robust object-level prior that enhances video segmentation, even in cases of occlusion and rapid motion.
( arxiv | code )

Junfeng Wu*, Qihao Liu*, Yi Jiang, Song Bai, Alan Yuille, Xiang Bai
(*Equal contribution)
European Conference on Computer Vision (ECCV), Oral, 2022
[TL;DR] We identify the main cause of the performance gap between online and offline VIS models and propose IDOL, a contrastive learning-based online framework that, for the first time, surpasses all offline methods across three benchmarks.
( PDF | code (☆ 605) | 1-st place solution for CVPR2022 VIS workshop )
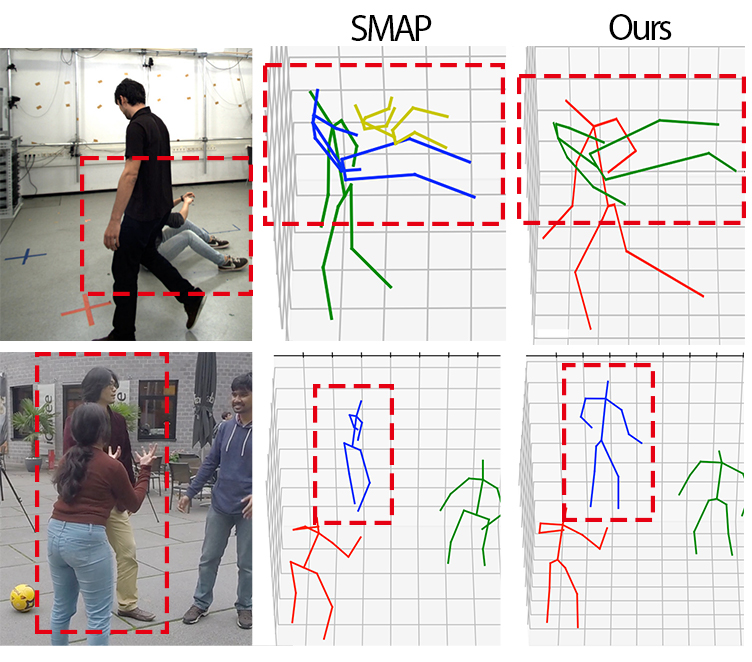
Qihao Liu, Yi Zhang, Song Bai, Alan Yuille
European Conference on Computer Vision (ECCV), 2022
[TL;DR] HUPOR leverages visible cues to infer occluded joints, significantly improving bottom-up multi-person human pose estimation, even in occluded scenarios.
( PDF | code )
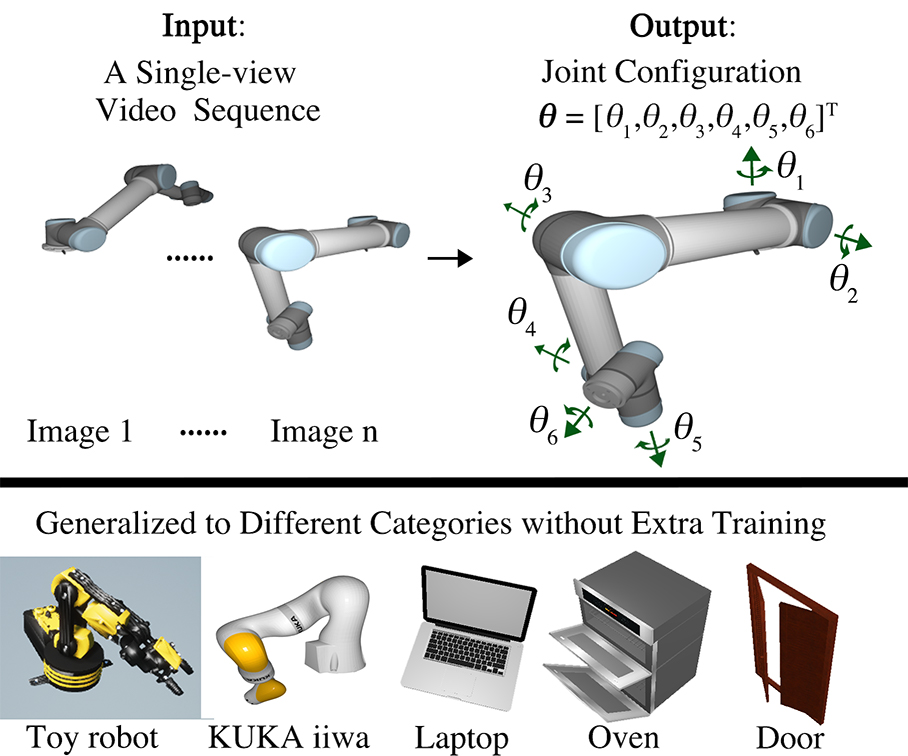
Qihao Liu, Weichao Qiu, Weiyao Wang, Gregory Hager, Alan Yuille
( arxiv )