| We propose DiMR, a new diffusion backbone that achieves state-of-the-art image generation. |












Highlights
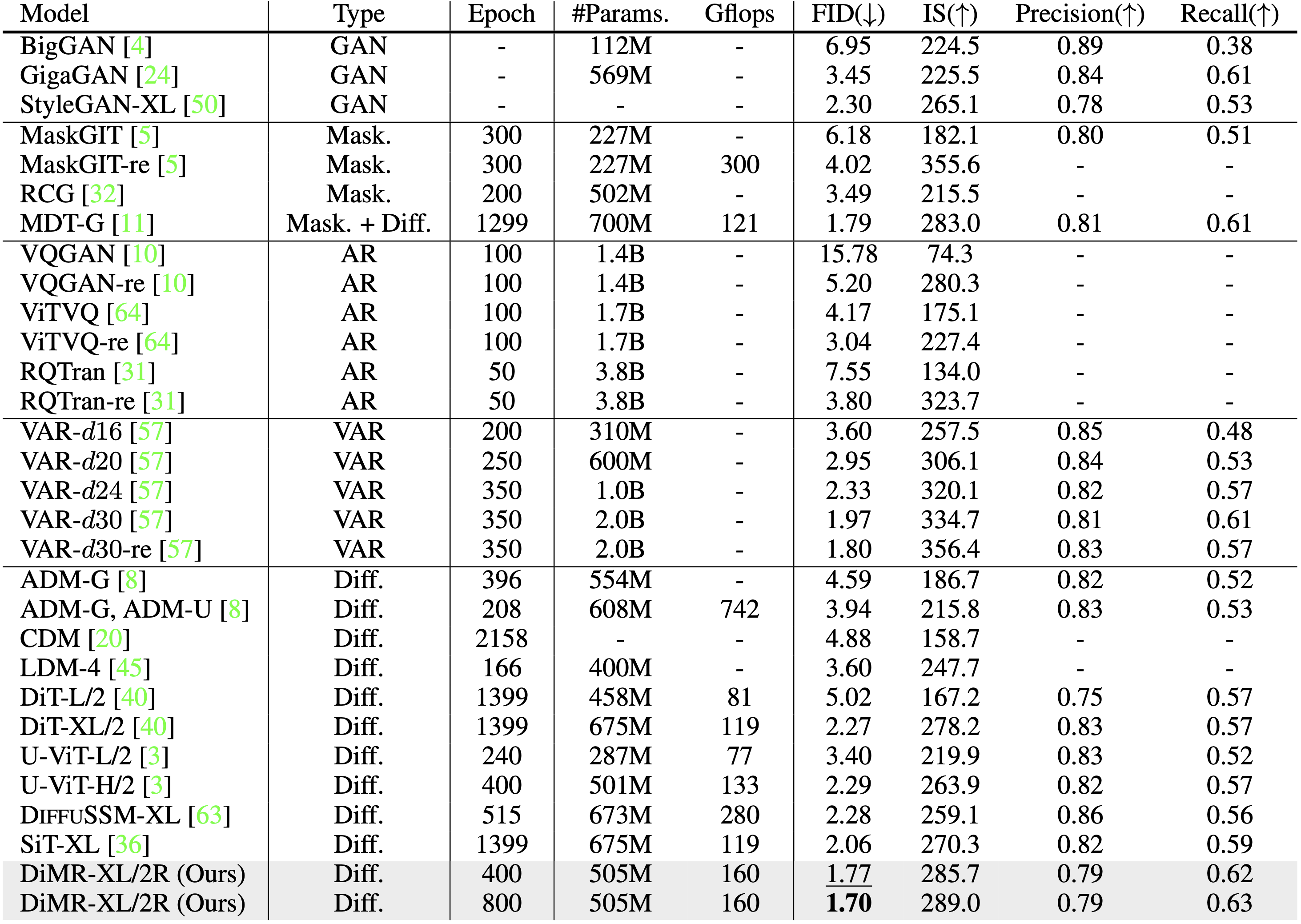

| In this figure, we randomly visualize the detected low-fidelity images, identified by a pretrained classifier, which are generated by the best models from the baselines and our DiMR. |
Abstract
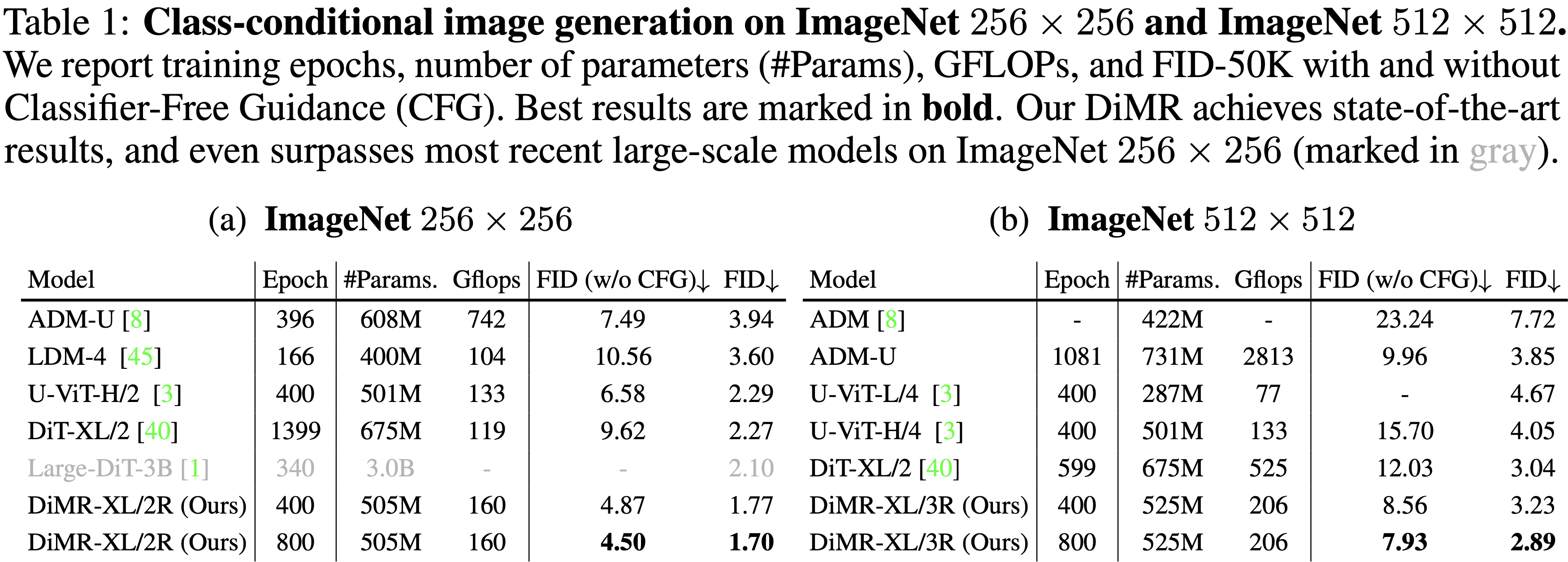
This paper presents innovative enhancements to diffusion models by integrating a novel multi-resolution network and time-dependent layer normalization. Diffusion models have gained prominence for their effectiveness in high-fidelity image generation. While conventional approaches rely on convolutional U-Net architectures, recent Transformer-based designs have demonstrated superior performance and scalability. However, Transformer architectures, which tokenize input data (via "patchification"), face a trade-off between visual fidelity and computational complexity due to the quadratic nature of self-attention operations concerning token length. While larger patch sizes enable attention computation efficiency, they struggle to capture fine-grained visual details, leading to image distortions. To address this challenge, we propose augmenting the Diffusion model with the Multi-Resolution network (DiMR), a framework that refines features across multiple resolutions, progressively enhancing detail from low to high resolution. Additionally, we introduce Time-Dependent Layer Normalization (TD-LN), a parameter-efficient approach that incorporates time-dependent parameters into layer normalization to inject time information and achieve superior performance. Our method's efficacy is demonstrated on the class-conditional ImageNet generation benchmark, where DiMR-XL variants outperform prior diffusion models, setting new state-of-the-art FID scores of 1.70 on ImageNet 256 x 256 and 2.89 on ImageNet 512 x 512.
Multi-Resolution Network

We propose DiMR that enhances Diffusion models with a Multi-Resolution Network. In the figure, we present the Multi-Resolution Network with three branches. The first branch processes the lowest resolution (4 times smaller than the input size) using powerful Transformer blocks, while the other two branches handle higher resolutions (2 times smaller than the input size and the same size as the input, respectively) using effective ConvNeXt blocks. The network employs a feature cascade framework, progressively upsampling lower-resolution features to higher resolutions to reduce distortion in image generation. The Transformer and ConvNeXt blocks are further enhanced by the proposed Time-Dependent Layer Normalization (TD-LN).
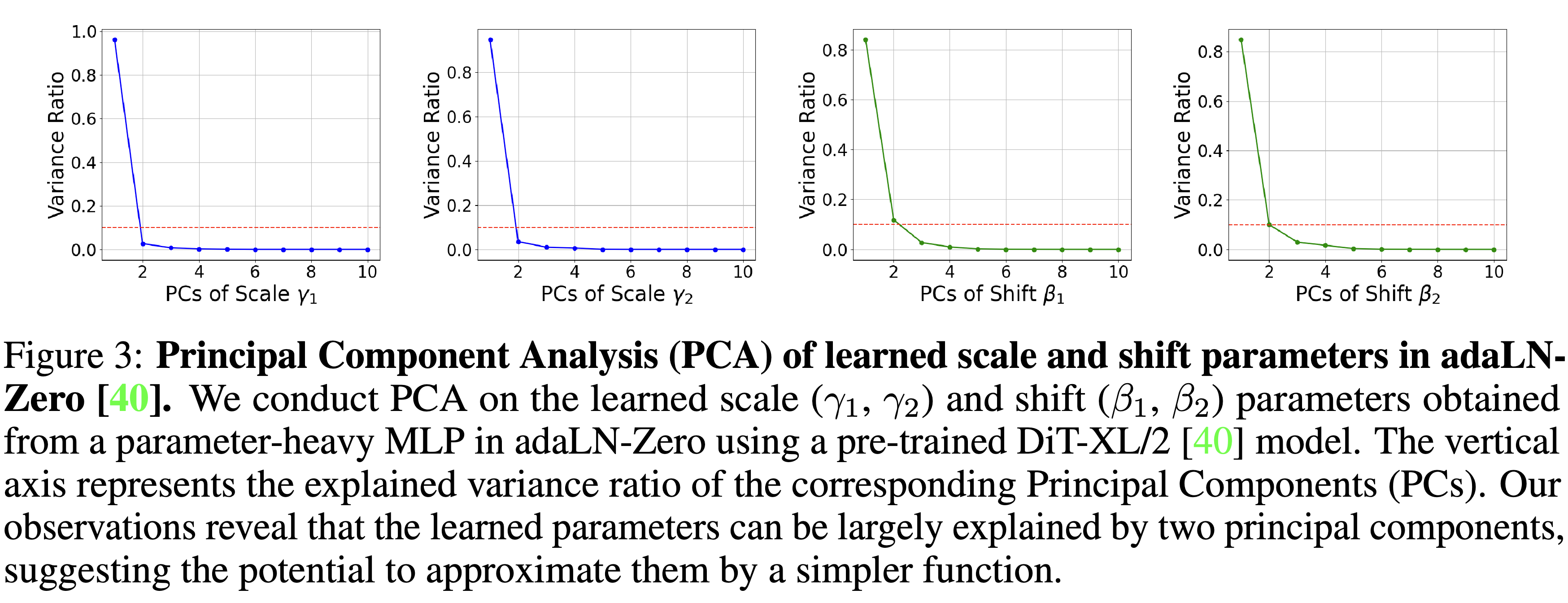
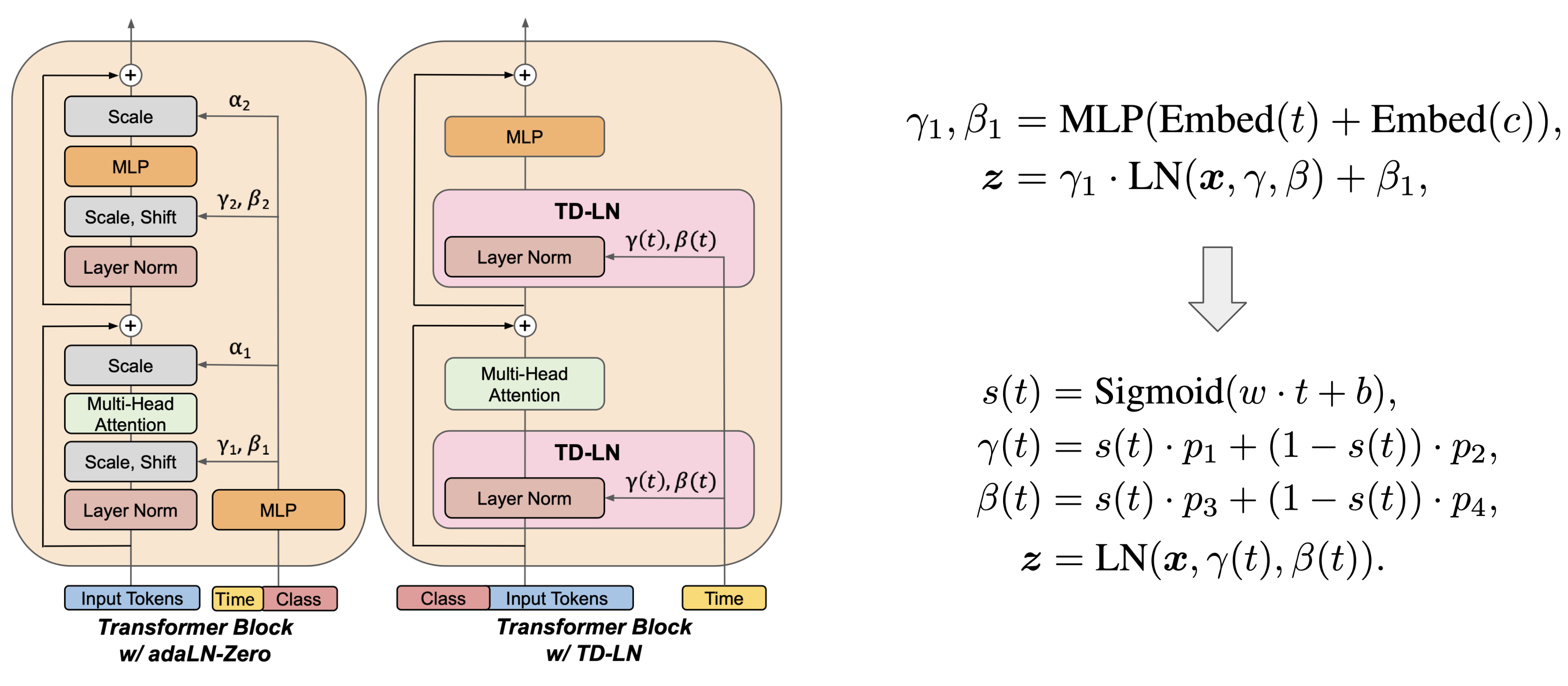
Time-Dependent Layer Normalization
Main Experimental Results
Bibtex